![]()
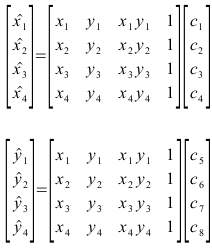
A number was assigned to each object, then from the equation object k was assigned to group i that has the maximum fi.
The process was then repeated on the test set images to investigate whether it classifies the object under their correct class.
From the last activity, I've chosen the kwek-kwek and pillows to be the two different classes, mostly because they are the easiest to identify by observation alone, just to simplify the automatic process. The chosen features to act as predictor variables are the same features chosen in activity 18.
The training set:

Obtained f1 and f2 values.
f1 f2
9420.1989 9419.4684
9752.2214 9751.3123
9731.9091 9731.8893
9710.5355 9709.5048
9679.0613 9679.2533
9834.2301 9835.7252
9662.9102 9663.0224
9436.1618 9436.3873
as we can see from the table above, knowing that the first 4 objects are kwekkweks (class 1) and the last 4 objects are pillows (class 2), and from the definition, we see that the higher value indicates under which class the object is/should be classified.
Now for the test set, the last 4 objects from the two classes, we go through the same process. To see if the method actually works, I rearranged the objecs so that the objects per class are alternating.
f1 f2 actual class obtained class
25342.328 25339.928 1 1
25854.604 25856.165 2 2
25720.845 25718.925 1 1
25634.751 25636.706 2 2
25789.394 25787.821 1 1
25232.292 25234.612 2 2
25428.663 25426.628 1 1
25849.122 25851.031 2 2
The method successfully classified the objects under their correct classes even after they were rearranged.
**I give myself a grade of 10 for this activity since the classification was 100% accurate with the expected.
**Thank you to cole fabros










![[ncc.jpg]](http://4.bp.blogspot.com/_6ZpN6X5LZPw/SL0FXYODUJI/AAAAAAAAAhw/pGj2mmL1yDk/s1600/ncc.jpg)


![[rgcc.jpg]](http://3.bp.blogspot.com/_6ZpN6X5LZPw/SL0HAiF92HI/AAAAAAAAAh4/_TufRbVLtT4/s1600/rgcc.jpg)